Databaseless Java-Native Persistence
EclipseStore is a breakthrough Java-native persistence layer built for cloud-native Java applications and microservices.
EclipseStore runs also on Android mobile, edge, and embedded devices.
Latest Version 1.3.2.
Ultra-fast In-Memory Data Processing
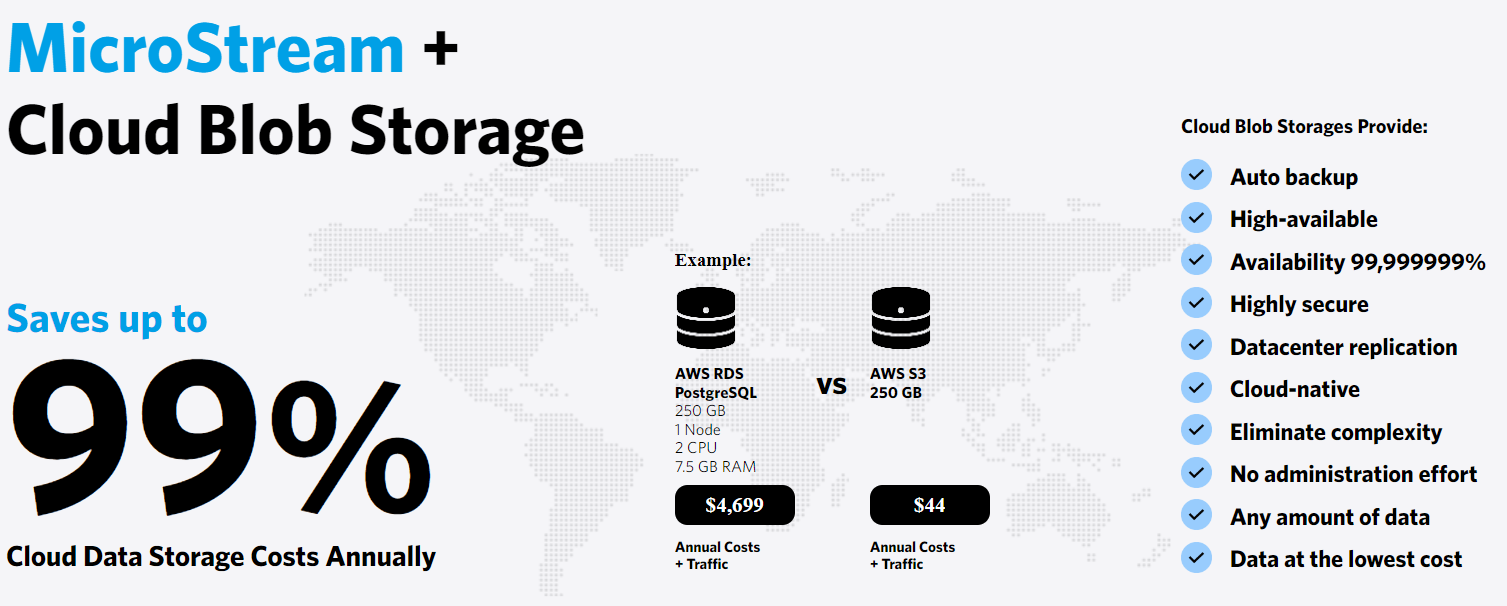
Lowest Data Storage Costs in the Cloud
Revolutionary Simple Development

Serialize Your Application Data
Directly into the Cloud
EclipseStore is a databaseless Java-native persistence layer built for cloud-native microservices and serverless systems. EclipseStore is the only data storage solution that uses the native Java object model instead of database-specific structure or format. It enables storing any Java object graph of any size and complexity transaction-safe seamlessly into any binary data storage such as plain files, persistent volumes or cloud object storage such as AWS S3. Snapshots of the object graph diffs are regularly saved to the storage and the ACID transaction journal guarantees full consistency. Each diff is stored as a bytecode representation appended to the storage using Eclipse Serializers highly optimized byte format. Objects are retrieved from the storage and restored in memory fully automated by just accessing the objects in your object graph via getter. Lazy-Loading enables to run EclipseStore also with low memory cpacity even lower than 1 GB. At system start, only object IDs are loaded into RAM. Related object references (subgraphs) are restored in memory on-demand only. Using EclipseStore is really simple.
Java-native object graph persistence layer
EclipseStore uses the native Java object model. No more database-specific data structure or format. No mappings or data conversion. No impedance mismatch.
Live mirroring of system state by creating micro snapshots
Snapshots of the object graph changes (the delta) are regularly serialized to disk transaction-safety and full consistent.
Warp-speed in-memory data processing
Your Java object graph in RAM becomes an ultra-fast Java in-memory database providing microsecond response & query time.
Big memory is perfect, but works also with low memory
At smaller RAM size just keep hot data in RAM. With lazy-loading you can restore only what's needed.
Waver-thin persistence layer
Smallest persistence layer for Java. No magic. No heavy-weight dependencies. Pure-Java. Built for microservices & serverless.
Cloud-native data storage
Connect your Java apps and microservices seamlessly with cloud-native data storage services.
Open Source
EclipseStore is open-source under EPL (Eclipse Public License) 2.0.
Distributed & highly scalable
Elastic horizontally scaling of EclipseStore apps is an enterprise feature provided by MicroStream.
Run everywhere
Runs wherever a JVM from Java 11 is available. On-prem, public cloud, containers, GraalVM native images, and Android devices.
Frameworks using EclipseStore



Fantastic Benefits
Java In-Memory Data Processing is Up to 1000x Faster than JPA + Tradiational RDBMS.
About this Demo
This is a trivial bookstore demo. 2 apps are running in parallel and different database queries are constantly being executed. One app is built with Hibernate, using a hot EHCache and a PostgreSQL database. The other app is built with EclipseStore using AWS S3 as storage. The code is available on GitHub.
| Persistence | EclipseStore |
|---|---|
| Cache | None |
| Data Storage | AWS S3 |
| Database size | 250 GB |
| Query API | Java Streams |
| Persistence | Hibernate |
|---|---|
| Cache | EHCache |
| Data Storage | PostrgreSQL |
| Database size | 250 GB |
| Query API | Spring Data, SQL |
Fully In-memory data processing
Your object graph in memory becomes an ultra-fast in-memory data store.
Microsecond response time, up to 1000x faster queries
Common database queries take milliseconds, with Core Java only microseconds.
Gigantic workloads and data throughput
The high performance enables to handle gigantic loads and throughput.
High-frequency low-latency transactions
Predestined for high-frequency transactions that require the lowest possible latency.
Real-time responsiveness
For systems that need high performance and real-time responsiveness.
Just Java VM power
Use the incredible high-speed of Core Java and the JVM for your data processing.
Supported Providers:



EclipseStore Simplifies & Accelerates Your Entire Database Development Process

- No more external database systems
- Only 1 data model: Java classes (POJOs)
- Mappings & data conversion eliminated
- Fully free data model design
- No more classic Selects, just call getter
- No more database-specific query language
- Tons of boilerplate code eliminated
- Use & store any Java types
- Pure Java approach
- Fits with all Java concepts
- Fully object-oriented
- Leads to a simple architecture
- Convenient API
- Easy data migration
Freely Data Model Design. No More Limitations.
EclipseStore lets you design your object model fully free without any technical requirements or restrictions. You can use and combine any Java type and use your object graph as a powerful multi-model data structure. You can also use circular references trouble-free, while the depth of your object graph is unlimited. Whatever your object model will look like, EclipseStore will be able to store it. There are no specific design rules, but to get maximum searching performance, you should design your object model for the best possible traversability.
Data model: Java object graphs
EclipseStore uses the native object model of Java, just POJOs.
- Any object graph structure
- Number of objects is unlimited
- Number of edges is unlimited
- Circular references
Multi-model data structure
Java object graphs are a multi-model data structure.
- Use any Java types
- Use collections
- Use any document format
- Custom type handling
- Combine everything
No specific design rules
Design your object model freely. No specifications by EclipseStore.
- No design specifications
- No limitations
- Just apply common OO design
Some Code
Use Plain Java Objects.
No Specific Requirements.
Beautiful Clean Code.
Your Java classes define your data model. With EclipseStore, there are no specific requirements to your classes. You can just use plain Java objects (POJOs). There is no need for specific superclasses, interfaces, annotations, mappings, or any other internal configurations.
- Use plain Java objects (POJOs)
- No superclass, interfaces, annotations
- No other internal configurations required
- All Java types supported
- Using inheritance is trouble-free
public class Customer {
private String firstname;
private String lastname;
private String email;
private LocalDate dateOfBirth;
private Boolean active;
private Set<Order> orders;
...
}
DataRoot root = EclipseStoreDemo.root();
root.getCustomers().add(customer);
EclipseStoreDemo.store(root.getCustomers());
Storing Objects
ACID Transaction-Safe
To persist objects in the storage, you just have to call one simple store method. By default, EclipseStore persists only new and changed objects (the delta). You decide explicitly, if and when objects are persisted. The data is stored as binary data appended to the file storage. Every store is an atomic all-or- nothing operation which is ACID transaction-safe and full consistent.
- Atomic all-or-nothing operation
- ACID transaction-safe
- Full consistency
- Append-log strategy
- Micro snapshot to store latest changes (delta)
- Rollback of in-memory ops
- High IO speed by Eclipse Serializer
- Max IO speed by using parallel IO ops
Lazy-Loading.
Restore Subgraphs On-Demand to Run Small RAM Machines.
With lazy-loading, particular object references are loaded and restored in RAM only when accessed, otherwise, no memory is allocated. At any time, lazy references can also be cleared to reduce memory consumption. Objects that are not defined as lazy are loaded and restored in RAM automated on system start.
- Size and depth of lazy references are unlimited
- Loaded object references are merged into the object graph fully automated
- Clearing lazy references is possible
- Working copies to simplify concurrency handling
- Max IO speed by using parallel IO ops
public class Customer {
...
private Lazy<Set<Order>> orders;
...
public Set<Order> getOrders() {
return Lazy.get(this.orders);
}
public void setOrders(final Set<Order> orders) {
this.orders = Lazy.Reference(orders);
}
...
}public class Customer {
...
private Lazy<Set<Order>> orders;
...
public Set<Order> getOrders() {
return Lazy.get(this.orders);
}
public void setOrders(final Set<Order> orders) {
this.orders = Lazy.Reference(orders);
}
...
}
Searching & Filtering
in Microseconds
Instead of querying a remote database server, just search your object graph in memory by using Java Streams. The Streams API is an enormously powerful and fully typesafe Java API for searching object graphs highly efficiently. Searching even giant and complex object graphs by iterating thousands of nodes takes only microseconds.
- No more database-specific query languages
- Java Streams API
- GraphQL
- Type-safe query API
- Ultra-fast in-memory execution
- Creating custom indexes
- Microsecond query time
- Low-latency realtime responsiveness
- Gigantic throughput and workloads
Class Changes Handling
Changes to classes can result in incompatible objects in your storage. With EclipseStore, changes to your classes are hassle-free and handled on the fly. If a loaded object no longer fits its corresponding class, the object will be adapted automatically. Simple cases are covered by a heuristic. For more complex cases, you can define a type mapping. Finally, the updated object has just to be persisted again to add a new object version to the storage. You can either keep older object versions or let EclipseStore remove them from the storage.
- Field added
- Field renamed
- Field removed
- Certain primitive type changes (int >> float)
- Custom type handler for any changes
public class Customer {
private String firstname;
private String lastname;
private String email;
private LocalDate dateOfBirth;
private Boolean active;
private Set<Order> orders;
...
}
Storage Garbage Collection
To min the required storage capacity, EclipseStore provides a garbage collection process to clean up the storage. Legacy object versions as well as corrupt files are constantly removed from the storage behind the scenes fully automated. The GC also reorganizes and defragments the storage to optimize read performance. The EclipseStore GC process is highly configurable.
Access Your Data:
Easy. Transparent. Any Time. By Using Standards.

Access by external applications & services
With REST and GraphQL you can provide any external system easily access your in-memory data.
Administration
EclipseStore provides you with a web app as well as a REST interface to access your storage data for admin purposes.
Easy migration in both directions
By using CSV Import/Export or other converters, any data can be migrated at any time in both directions easily.
Data Storage Viewer
EclipseStore provides you a web interface with a hierarchical view on your data storage. You can use it to browse through you entire storage. As an alternative, EclipseStore provides you also a REST interface to get access to your storage.
For Micro Machine Images and Big-RAM Machines
EclipseStore runs on any machine. To run cloud-native microservices or serverless functions, you can run EclipseStore on micro machines. But, EclipseStore also runs on big RAM machines. The more RAM available, the better the performance. Using EclipseStore with modern JVMs, you can process up to 16 TB of data in memory trouble-free. Thus, the suited machine size only depends on your use case.

- Loading data on-demand only
- Fast startup time
- Microservices & serverless approach

- You can keep the whole database in RAM
- Max performance
- Lowest possible latency
- Monolithic single node app approach
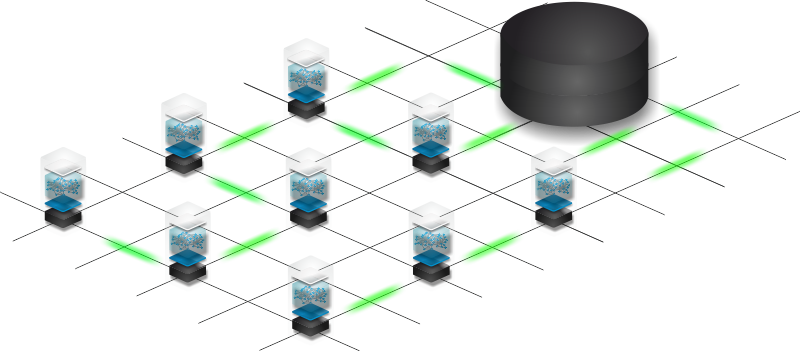
Distributed EclipseStore Apps with MicroStream Cluster
Build distributed EclipseStore apps & microservices with MicroStream Cluster, available as managed cloud service and on-prem. Note: MicroStream Cluster is a commercial add-on!
- Replication
- Elastic horizontally scalable
- Gigantic loads & throughput
- Low latency & realtime data
- High availability & resilience
- Enterprise-grade security & support
- Simple setup & maintenance
- Available as SaaS or On-Prem
Supported Storages
EclipseStore stores your Java object graph in a binary format and enables you basically to use any data storage. EclipseStore comes with various data storage connectors.















Use any JVM Technology

Support
EclipseStore Project
Only free community support without any guarantees or claims.
- Open Source
EclipseStore is under EPL 2.0 (Eclipse Public License). You may use EclipseStore for any commercial purposes and closed-source software. - All features included
- Updates
Updates are only provided for the current major release. - Issues & feature requests
Via GitHub Issues, no guarantees, claims or binding response time. - Questions & Answers
Via GitHub Discussions, no binding response time, not official support channel.
Enterprise Support
Recommended for mission-critical applications and software products. Provided by MicroStream.
- Long-term update warranty
- EclipseStore updates for all major releases for 4 years
- Eclipse Serializer format support for 10 years
- First-class development support
Ticket system, hotline, code reviews, consulting, implementation service, training courses & coaching - Enterprise-grade security
- Hotfixes
- Production support (24/5, 24/7)